# 使用自定义视觉和 Python 创建您的第一个模型
欢迎阅读 AI for Developer 系列的第一篇文章,在这个系列文章中,我将与大家分享有关 Azure AI 的一些技巧和窍门。我的名字是 Henk Boelman,在微软荷兰任 Cloud Advocate,专注于为开发者提供 AI 相关技术。
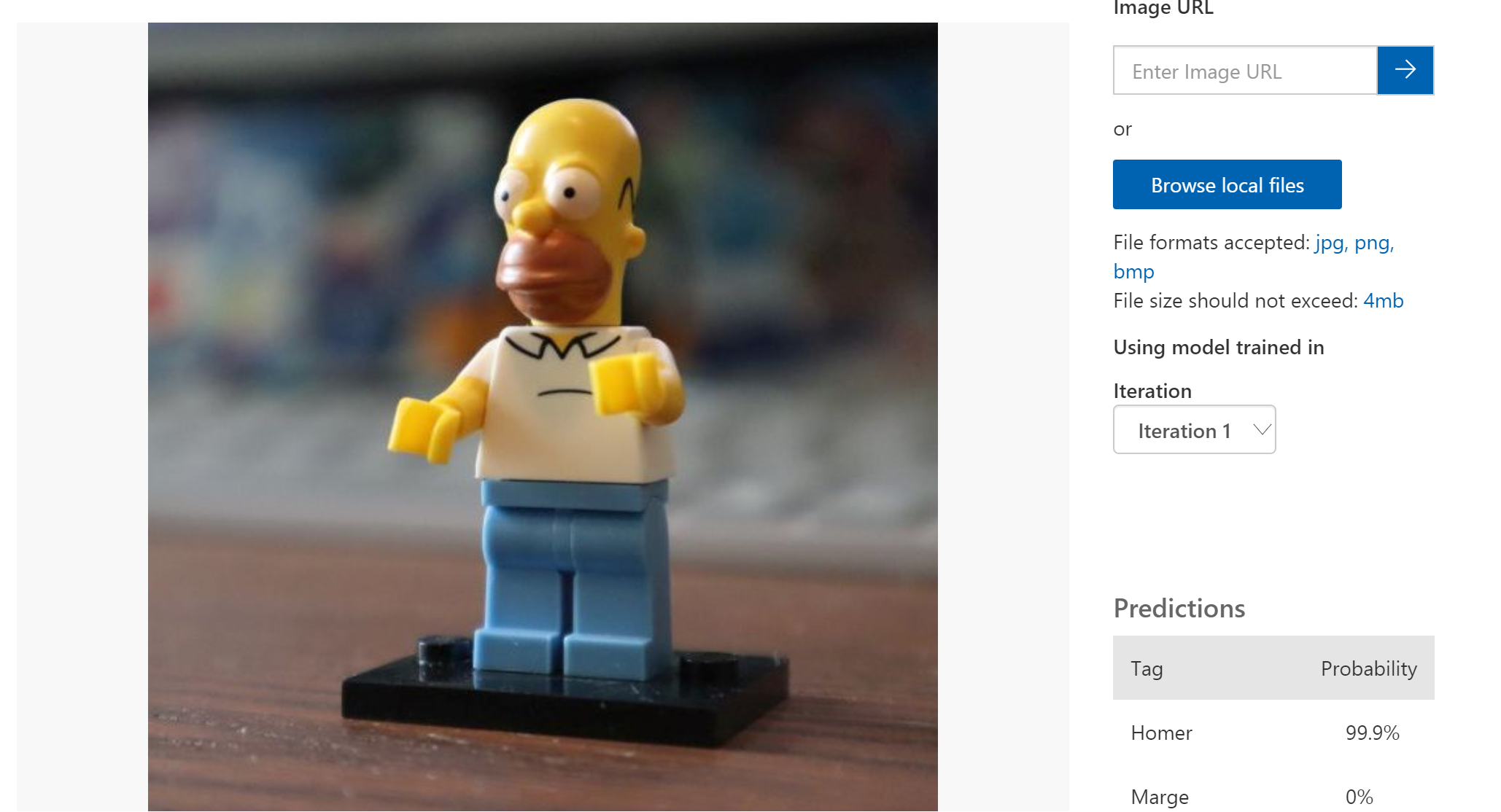
在第一篇文章中,我想与大家分享如何使用自定义视觉服务的 Python SDK 创建分类模型。
# 为什么使用 Python 而不是可视化界面?
这个问题的答案很简单,如果您使用代码进行训练,可以将其版本化,如托管在 Github 上。将代码版本化意味着您可以知道您做了什么,与团队一起工作,在需要的时候可以再次运行它。
让我们来深入研究下代码。在开始之前,请确保您已安装了 Python 3.6 (opens new window)。
# 在 Azure 中创建资源
您要做的第一件事是创建一个Azure自定义视觉服务。如果您还没有Azure 订阅 (opens new window) ,第一个月可以免费得到200美元额度。
您可以通过门户网站很容易地创建一个 Azure 自定义视觉的终结点,但您也可以使用 Azure CLI (opens new window)。如果您还没有安装 Azure cli (opens new window),可以通过 pip 安装它。
pip install azure-cli
第一步是登录到您的Azure订阅,选择正确的订阅,并为自定义视觉终结点创建资源组。
az login
az account set -s <SUBSCRIPTION_ID>
az group create --name CustomVision_Demo-RG --location westeurope
自定义视觉服务有两种类型的终结点。一个用于训练模型,一个用于运行针对模型的预测。
下面让我们创建这两个终结点。
az cognitiveservices account create --name CustomVisionDemo-Prediction --resource-group CustomVision_Demo-RG --kind CustomVision.Prediction --sku S0 --location westeurope –yes
az cognitiveservices account create --name CustomVisionDemo-Training --resource-group CustomVision_Demo-RG --kind CustomVision.Training --sku S0 --location westeurope –yes
您可以使用 Azure CLI 轻松获得终结点的训练密钥和预测密钥。
az cognitiveservices account keys list --name CustomVisionDemo-Training --resource-group CustomVision_Demo-RG
az cognitiveservices account keys list --name CustomVisionDemo-Prediction --resource-group CustomVision_Demo-RG
现在,我们已经创建了可以用来开始训练模型的终结点。
# 从一个问题开始
每一个机器学习之旅,都从一个问题开始。在这个例子中,您要回答这样的问题:他是乐高人物中的 Homer 还是 Marge。
现在我们知道要问模型什么问题,我们可以继续下一个需求:即数据。我们的模型将是一个分类模型,这意味着该模型将查看图片并对不同类别的图片打分。因此,输出将是我70%确信这是 Homer,1%确信这是 Marge。通过采取得分最高的分类,并设置置信度分数的最低门槛,我们将知道照片上有什么。
我已经为您创建了一个数据集,包含50张乐高积木中 Homer Simpson 的照片和50张 Marge Simpsons 的照片。我在拍摄照片时考虑了几个方面,使用了很多不同的背景并从不同的角度拍摄照片。我确信照片中的唯一对象就是 Homer 或 Marge,并且照片的质量在某种程度上是一致的。
# 训练模型
对于训练,我们会使用 自定义视觉服务 Python SDK (opens new window),您可以使用 pip 安装该软件包。
pip install azure-cognitiveservices-vision-customvision
创建一个名为 “train.py” 的新 Python 文件,并开始添加代码。
引入所需的包。
from azure.cognitiveservices.vision.customvision.training import CustomVisionTrainingClient
from azure.cognitiveservices.vision.customvision.training.models import ImageFileCreateEntry
接下来,为自定义视觉终结点、自定义视觉训练密钥和训练图片的存储位置创建变量。
cv_endpoint = "https://westeurope.api.cognitive.microsoft.com"
training_key = "<INSERT TRAINING KEY>"
training_images = "LegoSimpsons/TrainingImages"
要开始训练,我们需要创建一个训练客户端。这个方法将接收终结点和训练密钥作为参数。
trainer = CustomVisionTrainingClient(training_key, endpoint= cv_endpoint)
现在,您可以创建自己的第一个项目。该项目需要一个名称和域作为输入,名字可以是任何东西,域则有所不同。您可以查询所有可能的域的列表,并选择一个最接近您任务的域。举例来说,如果您想对食物进行分类,则选择域“Food”,或对地标分类选择“Landmarks”。使用下面的代码来显示所有域。
for domain in trainer.get_domains():
print(domain.id, "\t", domain.name)
您可能会发现有些域旁边有单词“Compact”。如果有这个词,意味着 Azure 自定义视觉服务将创建一个较小的模型,您能够将其导出并在手机或桌面上运行。
让我们创建一个设置为“General Compact”域的新项目。
project = trainer.create_project("Lego - Simpsons - v1","0732100f-1a38-4e49-a514-c9b44c697ab5")
接下来,您需要创建标签,这些标签即前面提到的分类。当创建了一些标签后,我们可以对图片进行标记并上传到 Azure 自定义视觉服务。
我们的图片已存放在每个标签/分类的文件夹中。Marge 的所有照片都存放在“Marge”文件夹中,Homer的所有照片都在“Homer”文件夹中。
在下面的代码中,我们将实现以下步骤:
- 打开包含训练图片文件夹的目录
- 循环该目录中的所有子文件夹
- 使用文件夹名称创建一个新标签
- 打开包含图片的文件夹
- 为该文件夹中的所有图片创建一个 ImageFileEntry,其中包含文件名,文件内容和标签
- 将该ImageFileEntry添加到一个列表
image_list = []
directories = os.listdir(training_images)
for tagName in directories:
tag = trainer.create_tag(project.id, tagName)
images = os.listdir(os.path.join(training_images,tagName))
for img in images:
with open(os.path.join(training_images,tagName,img), "rb") as image_contents:
image_list.append(ImageFileCreateEntry(name=img, contents=image_contents.read(), tag_ids=[tag.id]))
现在您已经有了一个包含所有已标记过的图片列表。到目前为止,还没有任何图片被添加到 Azure 自定义视觉服务中,只创建了一些标签。
批量上传图片时,每批次的最大数量为 64 个图片。我们的数据集包括 100 个图片,所以我们需要将列表按 64 进行分割。
def chunks(l, n):
for i in range(0, len(l), n):
yield l[i:i + n]
batchedImages = chunks(image_list, 64)
现在,我们有了按 64 进行分割的图片集,可以批量上传到 Azure 自定义视觉服务了。 注:这可能需要一段时间
for batchOfImages in batchedImages:
upload_result = trainer.create_images_from_files(project.id, images=batchOfImages)
目前为止,在通过 API 终结点访问模型之前,只剩下两个步骤了。首先,需要训练模型,最后必须发布模型,从而可以通过预测 API 访问。训练可能需要一段时间,因此您可以在训练请求之后创建一个 while 循环,每秒钟检查模型的训练状态。
import time
iteration = trainer.train_project(project.id)
while (iteration.status != "Completed"):
iteration = trainer.get_iteration(project.id, iteration.id)
print ("Training status: " + iteration.status)
time.sleep(1)
现在,您已经到了最后一步,我们可以发布模型。这样我们可以通过预测 API 使用模型,并能够从应用程序访问它。
每次对模型进行训练的过程,称为迭代。通常当有新的数据或发现在实际应用中模型与预期结果不同时,必须重新训练模型。
自定义视觉服务的理念是,您可以以一个特定的名称发布模型迭代。这意味着您可以为应用程序使用模型的多个版本,例如,您可以方便的对模型进行 A-B 测试。
要发布您的模型迭代,需要调用 publish_iteration 方法,这个方法需要几个参数。
项目ID和迭代ID,这些是来自前面几个步骤的值。您可以为您的模型发布选择一个名字,比如“latest”或“version1”。您需要的最后一个参数是要发布到资源的“resource identifier”。这是我们在使用AZ命令最初创建 Azure 自定义视觉预测资源的资源标识符。
您可以使用此命令检索所有关于您所创建的预测资源的详细信息:
az cognitiveservices account show --name CustomVisionDemo-Prediction --resource-group CustomVision_Demo-RG
您可以复制 field ID 后面的值,如下所示:
/subscriptions/<SUBSCRIPTION-ID>/resourceGroups/<RESOURCE_GROUP_NAME>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>")
当您有了资源ID,将其粘贴在如下所示的变量中,并调用名为“publish_iteration”的方法。
publish_iteration_name = ''
resource_identifier = ''
trainer.publish_iteration(project.id, iteration.id, publish_iteration_name, resource_identifier)
现在您已经成功地训练并发布了您的模型!
让我们来做一下总结:
- 您创建了一个 Azure 资源组,包含Azure 自定义视觉服务的训练和预测终结点
- 您创建了一个新项目
- 在这个项目中,您创建了不同的标签
- 您按每组64个图片的方式上传了图片并对它们标记了标签
- 您对模型进行了训练迭代
- 您将迭代发布到预测终结点
# 对模型进行测试
使用应用程序中的模型非常简单,就像调用一个API一样。您可以将一个JSON使用POST方法发送到终结点,您也可以使用自定义视觉 Python SDK中的方法,这将更容易一些。
创建一个名为'predict.py'的新文件。
引入预测所需的依赖项。
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient
接下来是预测的关键。您需要从已发布模型的资源中获取密钥。您可以使用此AZ命令列出所有的密钥:
az cognitiveservices account keys list --name CustomVisionDemo-Prediction --resource-group CustomVision_Demo-RG
当拥有预测密钥时,您就可以创建一个预测客户端。对于这种客户端,您还需要一个终结点。您可以运行下面的AZ命令并复制“endpoint”字段后的URL。
az cognitiveservices account show --name CustomVisionDemo-Prediction --resource-group CustomVision_Demo-RG
现在有了预测密钥和终结点,可以创建 PredictionClient 了。
predictor = CustomVisionPredictionClient(prediction_key, endpoint=ENDPOINT)
您对图片进行分类时有多种选择。您可以发送一个URL,也可以将二进制图片发送到终结点。默认情况下,Azure 自定义视觉服务保留所有发送到终结点的图片历史。图片和其预测可以在门户网站进行审查,并用于重新训练模型。但有时您不想存储图片历史,也可以禁用此功能。
我已经上传了2张图片,您可以用来测试,但您也可以随意使用搜索引擎找到的其他图片:Marge (opens new window)和Homer (opens new window)。
要使用URL对图片进行分类并保存历史,需要调用“classify_image_url”方法。从前面的步骤中取得项目ID和迭代名称,传递给该方法,并提供一个图片的URL即可。
results = predictor.classify_image_url(project.id,publish_iteration_name,url="https://missedprints.com/wp-content/uploads/2014/03/marge-simpson-lego-minifig.jpg")
为了显示不同分类的分数,您可以通过下面的代码循环检测结果,并显示图片的标签名称和置信度分数。
for prediction in results.predictions:
print("\t" + prediction.tag_name + ": {0:.2f}%".format(prediction.probability * 100))
现在,所有工作已完成,您已在云中运行自己的分类模型!下面回顾一下您的工作:
- 提出一个问题
- 搜集数据
- 创建 Azure 自定义视觉服务终结点
- 创建新项目
- 上传图片内容并标记标签
- 训练模型
- 发布迭代并将其用于API
- 使用API预测模型
在本系列文章的其他部分,我们将对不同的解决方案使用这个模型!敬请关注!