# 在 Azure ML 上使用生成对抗网络(GAN)创建艺术作品
深度学习就像魔法一样!当看到神经网络进行一些创造性的工作时,比如学习艺术家的风格去绘画,这时候我会有一种神奇的感觉。这背后的技术叫做生成对抗网络,本文中我们将了解如何在Azure的机器学习服务上训练这样一个网络。
这篇文章是AI April计划的一部分,所谓AI April计划是我的同事会在四月的每一天发布新的有关AI,机器学习和微软的原创文章。可以点击 日历 (opens new window) 以查看更多已经发布的文章,找到你感兴趣的内容。
如果你我之前发布的有关Azure ML的文章(关于在VS Code内部使用Azure ML (opens new window) and 提交实验和超参数优化 (opens new window))。你应该会知道,将Azure ML用于几乎任何训练任务都很方便。但是,到目前为止,所有的示例都是用的MNIST测试数据集。如今我们将致力于解决现实问题:创造像这样的人工智能绘画作品:
 |  |
|---|---|
| 鲜花, 2019, 人工艺术 keragan (opens new window) 基于 WikiArt (opens new window) 鲜花的训练 | 混沌女王, 2019, keragan (opens new window) 基于 WikiArt (opens new window) 肖像的训练 |
这些绘画作品是在使用维基艺术进行绘画网络训练后被制作出来的。如果你想重现相同的结果,那你可能需要自己收集数据集,你可以使用维基艺术检索器 (opens new window), 或者浏览现有的来自[维基艺术数据集](https://github.com/cs-chan/ArtGAN/blob/master/WikiArt Dataset/README.md) 的收藏集。还可以通过GANGogh Project (opens new window)来获得.
将需要训练的图像放在数据集目录下的任意位置:
我们需要使用神经网络模型去学习花束和花瓶的高层次组成,以及低层次的油漆上色和画布纹理等绘画风格。
# 生成对抗网络
那些绘画作品是使用生成对抗网络 (opens new window)(简称GAN)生成的。在此示例中,我们将在Keras中使用我的简单GAN实现,称为keragan (opens new window),同时我将展示一部分简化的代码。
GAN由两个网络组成:
- 生成器, 根据给定的输入噪声矢量生成图片
- 识别器, 区分真实绘画和“假”(生成的)绘画的不同点
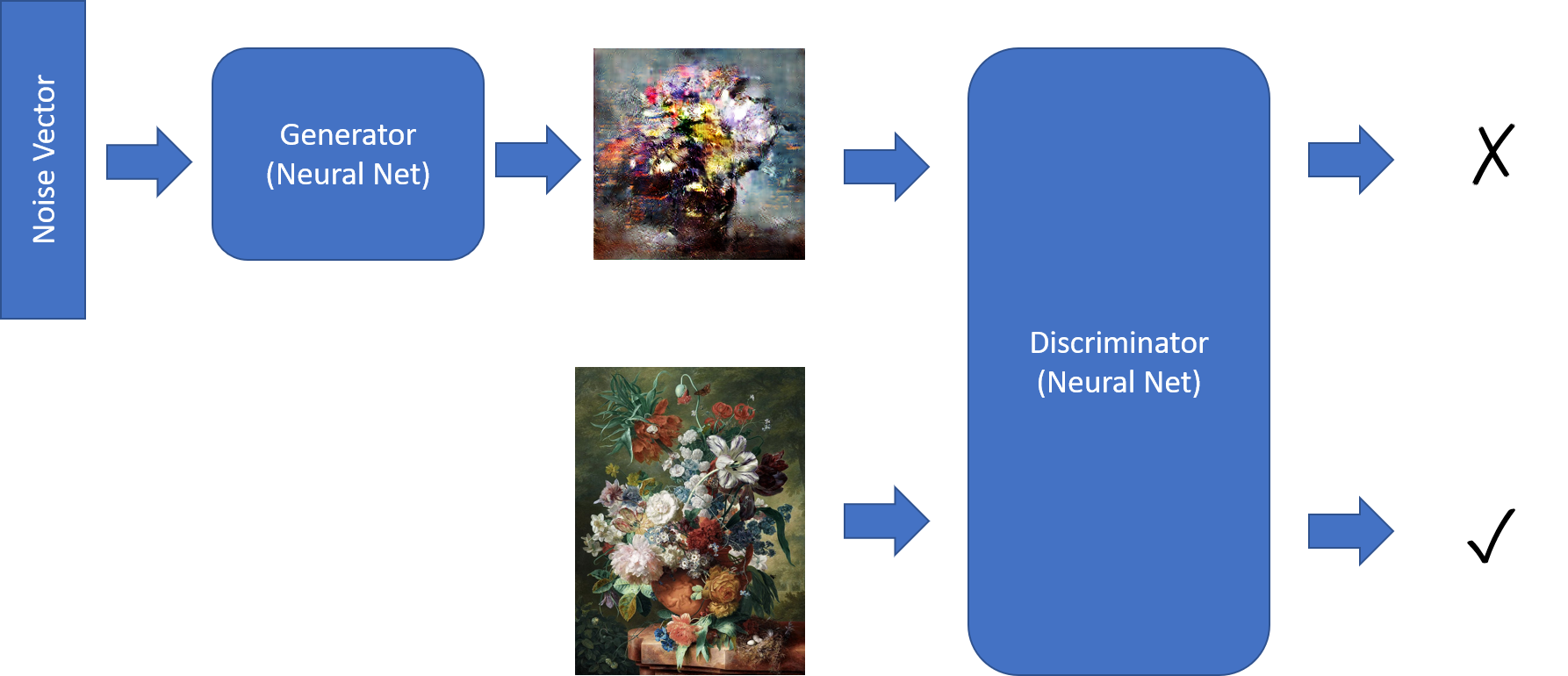
培训 GAN 涉及以下几个步骤:
获取一堆生成的和真实的图片:
noise = np.random.normal(0, 1, (batch_size, latent_dim)) gen_imgs = generator.predict(noise) imgs = get_batch(batch_size)训练识别器以更好的区分两者。注意:我们是提供向量值的方法
ones和zeros
期望的答案:
d_loss_r = discriminator.train_on_batch(imgs, ones)
d_loss_f = discriminator.train_on_batch(gen_imgs, zeros)
d_loss = np.add(d_loss_r , d_loss_f)*0.5
训练组合模型,以提升生成器
g_loss = combined.train_on_batch(noise, ones)
在此步骤中,不训练识别器,因为在创建组合模型期间,其权重被显式冻结:
discriminator = create_discriminator()
generator = create_generator()
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer,
metrics=['accuracy'])
discriminator.trainable = False
z = keras.models.Input(shape=(latent_dim,))
img = generator(z)
valid = discriminator(img)
combined = keras.models.Model(z, valid)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
# 识别器模型
为了区分真实图像和假图像,我们使用传统的 卷积神经网络 (opens new window)(CNN)架构。因此,对于尺寸为 64x64 的图像,我们将有类似这样的内容:
discriminator = Sequential()
for x in [16,32,64]: # number of filters on next layer
discriminator.add(Conv2D(x, (3,3), strides=1, padding="same"))
discriminator.add(AveragePooling2D())
discriminator.addBatchNormalization(momentum=0.8))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Dropout(0.3))
discriminator.add(Flatten())
discriminator.add(Dense(1, activation='sigmoid'))
我们有 3 个卷积层,它们负责执行以下操作:
- 形状为64x64x3的原始图像经过16层过滤器,产生一个形状为32x32x16的图像。为了减小文件大小,我们使用
AveragePooling2D。 - 下一步转换32x32x16的张量为16x16x32的张量。
- 最后,在下一个卷积层之后,我们最终得到8x8x64形状的张量。
在此卷积基础上,我们提出了简单的logistic回归分类器(AKA 1-神经元致密层)。
# 生成器模型
生成器模型稍微复杂一些。首先,假设我们想要将图像转换为某种长度latent_dim=100的要素矢量。我们将使用与上面的识别器类似的卷积网络模型,不同的是,识别器的最终层会是一个大小为100的密集层。
生成器的作用正好相反 – 将大小为100的矢量转换为图像。这涉及到一个称为去卷的过程,它本质上是一个反向卷积。与UpSampling2D一起使用时会导致每个层的张量尺寸增加:
generator = Sequential()
generator.add(Dense(8 * 8 * 2 * size, activation="relu",
input_dim=latent_dim))
generator.add(Reshape((8, 8, 2 * size)))
for x in [64;32;16]:
generator.add(UpSampling2D())
generator.add(Conv2D(x, kernel_size=(3,3),strides=1,padding="same"))
generator.add(BatchNormalization(momentum=0.8))
generator.add(Activation("relu"))
generator.add(Conv2D(3, kernel_size=3, padding="same"))
generator.add(Activation("tanh"))
在最后一步,我们以64x64x3的张量大小结束,这正是我们需要的图像的大小。请注意,最终的激活函数是 tanh,它给出的输出范围为[-1;1] ---- 这意味着我们需要将原始训练图像缩放到此区间。所有这些准备图像的步骤都由ImageDataset类来处理,我将不会在此详细介绍。
# Azure ML的训练脚本
现在,我们已经有了训练GAN的所有组件,接下来我们准备在Azure ML上运行一些实验代码!
然而,有非常重要的一点需要特别注意:当我们在Azure ML中运行实验时,通常希望追踪准确性或丢失等指标。我们可以在训练期间使用run.log来记录那些值,就像我的上一篇文章 (opens new window)中描述的那样,同时可以在Azure ML Portal (opens new window)中看到这些指标的变化情况。
但是在我们这个案例中,我们感兴趣的不是数字指标,而是网络在每个步骤中生成的可以看到的图像,在训练运行的状态下检查这些图像可以帮助我们决定是否结束实验,更高参数,或者是继续运行。
Azure ML除了支持记录数值之外还支持记录图像,具体请看此处 (opens new window)。我们可以记录呈现为np数组的图像,或者是由matplotlib生成的任何图表,因此我们将在一个图表上绘制三个示例图像。这个绘图过程将在每次训练之后由keragan调用的回调函数callbk中处理:
def callbk(tr):
if tr.gan.epoch % 20 == 0:
res = tr.gan.sample_images(n=3)
fig,ax = plt.subplots(1,len(res))
for i,v in enumerate(res):
ax[i].imshow(v[0])
run.log_image("Sample",plot=plt)
因此,实际的训练代码将看起来如下所示:
gan = keragan.DCGAN(args)
imsrc = keragan.ImageDataset(args)
imsrc.load()
train = keragan.GANTrainer(image_dataset=imsrc,gan=gan,args=args)
train.train(callbk)
注意:这代码之所以如此简单,是因为keragan支持自动解析多个命令行参数,我们可以通过args结构体来传递给它。
# 开始实验
提交实验到Azure ML时,我们将使用一段类似于在上一篇关于Azure ML的文章 (opens new window)中讨论过的代码。代码位于[submit_gan.ipynb][https://github.com/CloudAdvocacy/AzureMLStarter/blob/master/submit_gan.ipynb],它从熟悉的步骤开始:
- 使用
ws = Workspace.from_config()连接到工作空间 - 连接到计算集群:
cluster = ComputeTarget(workspace=ws, name='My Cluster')。此处我们需要一个带有GPU的虚拟机集群,例如NC6 (opens new window)。 - 上传我们的数据集到ML工作区默认的数据存储里
在这些步骤完成后,我们就可以使用如下代码提交我们的实验:
exp = Experiment(workspace=ws, name='KeraGAN')
script_params = {
'--path': ws.get_default_datastore(),
'--dataset' : 'faces',
'--model_path' : './outputs/models',
'--samples_path' : './outputs/samples',
'--batch_size' : 32,
'--size' : 512,
'--learning_rate': 0.0001,
'--epochs' : 10000
}
est = TensorFlow(source_directory='.',
script_params=script_params,
compute_target=cluster,
entry_script='train_gan.py',
use_gpu = True,
conda_packages=['keras','tensorflow','opencv','tqdm','matplotlib'],
pip_packages=['git+https://github.com/shwars/keragan@v0.0.1']
run = exp.submit(est)
在我们这个示例中,我们传递model_path=./outputs/models和samples_path=./outputs/samples作为参数,它们会指定训练期间生成的模型和样本数据写入到Azure ML实验的相应目录里。而那些文件将可以通过Azure ML门户访问到,也可以在训练结束后(甚至是训练进行期间)通过编写程序来下载到本地。
为了创建可以在GPU上顺利运行的Estimator,我们使用内建的Tensorflow (opens new window) Estimator。它和通用Estimator (opens new window)非常类似,但是可以为分布式训练提供开箱即用的选项。你可以去了解更多关于使用不同估算器的官方文档 (opens new window)。
另外一个有趣的点是我们可以直接从GitHun安装keragan库。尽管我们也可以从PyPI存储库安装,但我想向你展示它也支持直接从GitHub安装,你甚至可以指定库文件的特定版本,标签或者是提交ID。
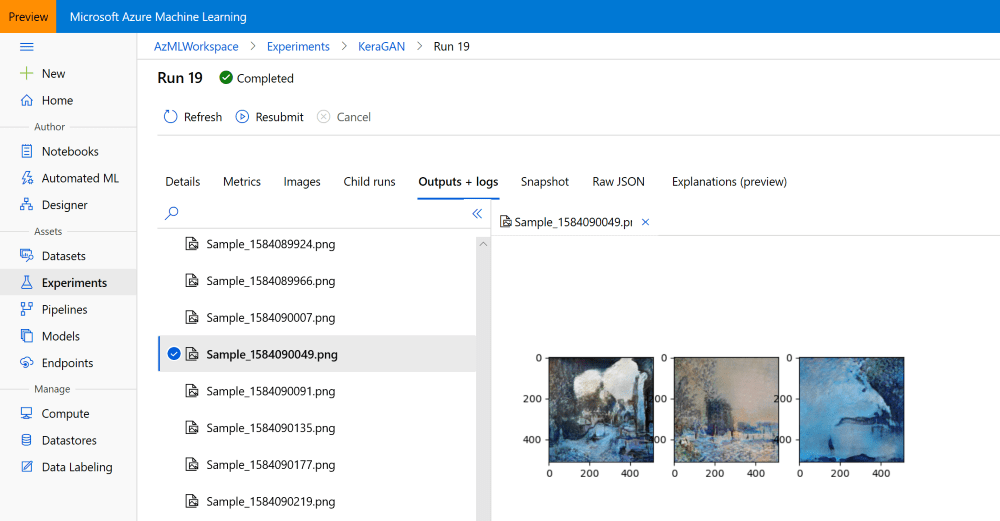
实验运行一段时间后,我们应该就可以在Azure ML 门户 (opens new window)中看到样本图片:
# 运行多个实验
首次运行GAN训练的时候,由于某些原因我们可能无法得到优异的结果。首先,学习速率似乎是一个重要的参数,过高的学习速率可能会导致不良的结果。因此,为了获得最佳效果,我们需要进行大量的实验。
可能想要修改的参数如下:
--大小这决定了图片的大小,数值应该是2的指数级。像64或者128这样的小型号可以让实验更迅速,然而大型号(最高可达1024)有利于生成高质量的图片。超过1024可能就无法产生一个好的结果,因为高分辨率的GANs需要特殊的技术来训练,比如 progressive growing (opens new window)。--学习速率是一个(令人惊讶的)相当主要的参数,尤其是对于高分辨率图像的训练。学习速率越小,训练的结果就越好,但同时也会非常的慢。--数据集我们可能会上传不同风格的图片到Azure ML数据存储中的不同文件夹里面,并同时开始训练多个实验。
因为我们已经知道如何以编程方式提交实验,所以应该很容易将代码包装成几个“for”循环来执行一些参数扫描。然后,您可以通过Azure ML门户手动检查哪些实验正在取得良好结果,并终止所有其他实验以节省成本。拥有一个由几个vm组成的集群可以让您自由地同时开始一些实验,而无需等待。
# 获得实验结果
当你对结果满意的时候,这些训练结果才有意义。如我之前提到的一样训练时我们的训练脚本会存储模型在outputs/models路径下,并存储示例图片在outputs/samples路径下。你可以在Azure ML 门户里面浏览这些路径,也可以手动将其下载下来:
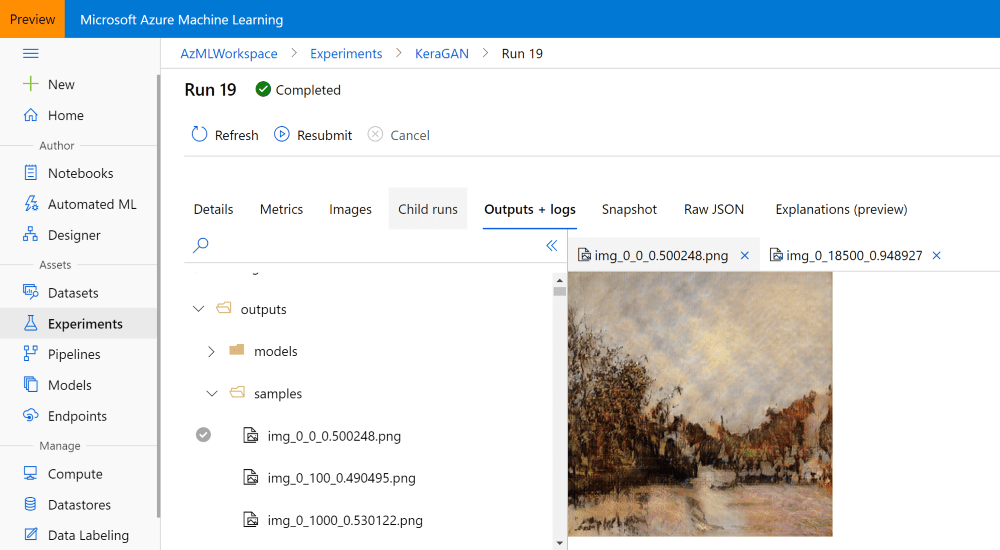
你也可以以编程方式执行此操作,特别是要下载不同时刻生成的所有图像。run表示在实验提交期间某一刻获得的对象,允许你访问运行期间某一刻的全部文件,而且你可以运行如下的脚本下载这些文件:
run.download_files(prefix='outputs/samples')
这将在当前路径下创建一个outputs/samples路径,并以相同的名称下载远程路径下的全部文件。
如果丢失了对笔记本内特定运行进程的引用(这可能会发生,因为大多数实验运行很长的时间),那么你始终可以通过Azure ML 门户上已知的run id来重新创建引用。
run = Run(experiment=exp,run_id='KeraGAN_1584082108_356cf603')
我们也可以获得经过训练的模型。比如,下载最终的生成器模型,并将其用于生成一组随机图片。我们可以获取与实验有关的所有文件名,然后筛选出生成器模型的文件名:
fnames = run.get_file_names()
fnames = filter(lambda x : x.startswith('outputs/models/gen_'),fnames)
她们看起来类似于outputs/models/gen_0.h5, outputs/models/gen_100.h5。我们需要找出最大阶段的数:
no = max(map(lambda x: int(x[19:x.find('.')]), fnames))
fname = 'outputs/models/gen_{}.h5'.format(no)
fname_wout_path = fname[fname.rfind('/')+1:]
run.download_file(fname)
这将下载具有较高纪元编号的文件到本地目录,并将此文件的名称存储在fname_wout_path。
# 生成新图像
获得模型后,我们只需要把模型加载到Keras里,找出输入大小,并给赋一个正确大小的随机矢量作为输入去生成一个新的随机绘画生成网络:
model = keras.models.load_model(fname_wout_path)
latent_dim=model.layers[0].input.shape[1].value
res = model.predict(np.random.normal(0,1,(10,latent_dim)))
生成网络的输出区间为[-1,1],因此我们需要线性缩放到区间[0,1]以便可以通过matplotlib准确显示:
res = (res+1.0)/2
fig,ax = plt.subplots(1,10,figsize=(15,10))
for i in range(10):
ax[i].imshow(res[i])
将会得到的结果:

这个实验期间产生的最佳图片:
 |  |
|---|---|
| 色彩缤纷的春天, 2020 | 乡村, 2020 |
| keragan (opens new window) 基于 WikiArt (opens new window) 印象派的训练 | |
 |  |
| 透过结冰的玻璃, 2020 | 夏日风景, 2020 |
| keragan (opens new window) 基于 WikiArt (opens new window) 印象派的训练 |
如果你想每天得到一张全新的来自这个生成网络的图片,我们(和我女儿一起)开通了一个Instagram账号@art_of_artificial (opens new window)来分享这些图片。
# 观察学习的过程
研究GAN网络逐渐学习的过程也是非常有趣的。我在人造艺术 (opens new window)展览中有探索这种学习的概念。下面这几个视频可以为你展示这个过程:
| GAN Flower Generation | GAN Portrait Generation |
|---|---|
| https://youtu.be/hnwbnt2Q9Iw (opens new window) | https://youtu.be/j2wpUFxyrEs (opens new window) |
# 值得深思的问题
本文中,我描述了GAN是如何工作的,以及如何使用Azure ML来训练它。这无疑为实验开辟了很多的空间,同时也引发了很大的思考空间。在这个实验中,我们创造了由人工智能生成的原创艺术品,但是它们真的可以被认为是艺术吗?我将会在下一篇文章中进行讨论……
##致谢
创造keragan (opens new window)库的时候,我深受一些文章的启发:this article (opens new window),来自Maxime Ellerbach的DCGAN implementation (opens new window)。并且有一部分来自GANGogh (opens new window)项目。此处 (opens new window)介绍了Keras实现的很多不同的GAN体系架构。