# 開始 Azure 機器學習的最佳方式
我知道許多資料科學家,包括我自己,都在配備 GPU 的機器使用 Jupyter Notebooks 或某些 Python IDE,也許本地端或在雲完成大部分工作。近兩年來,作為 AI/ML 軟體工程師,我在做沒有 GPU 的機器上處理資料,然後在雲中使用 GPU 虛擬機器做訓練。
另一方面,您可能已經聽說過Azure 機器學習 (opens new window)——一個特別的機器學習平台服務。但是,當你開始參考一些入門教程 (opens new window),您可能意識到,使用Azure 的ML 會繁瑣及重工產生很多不必要的開銷,使用過程不是很理想。例如,訓練腳本是透過 Jupyter Cell 的文本文件創建的,沒有編碼補全,也無法方便地在本地端執行或調校。這些額外的開銷也是我們並沒有在我們的項目中盡可能多的使用它的原因。
不過,最近我找到一個擴充Visual Studio Code Extension for Azure ML (opens new window)。透過這個擴充,您可以在 VS Code 中直接開發您的的訓練編碼,並在本地端運行,然後將相同的編碼提交到集群上進行訓練,這些過程只需幾下點擊。並且還有幾個重要的好處:
- 您可以將主要的時間花在本地機器上,並在需要訓練時使用強大的雲端GPU資源。訓練集群可以根據需求自動調整大小,當將機器的最小量設置為0後,你可以根據需要調整 VM。
- 您將訓練的所有結果包括指標和創建模型維護在一個中心位置,你不在需要手工為每個實驗保留精確度的記錄。
- 如果幾個人在同一項目上工作——他們可以使用同一個集群(所有實驗將進行排隊),並且可以查看彼此的實驗結果。例如,您可以使用教室環境中的 Azure ML,創建一個集群供所有人使用,而不是給每個學生創建一個單獨的 GPU 機器,並促進學生之間為模型精確度進行競爭。
- 如果您需要進行大量訓練,例如用於超參數優化——所有這些可以通過幾個命令來完成,無需手動運行一系列的實驗。
我希望已經說服您來嘗試一下 Azure ML!下面是如何開始使用的最佳方式:
- 安裝Visual Studio Code (opens new window), Azure Sign In (opens new window) 和Azure ML (opens new window) 擴展
- 克隆庫 https://github.com/CloudAdvocacy/AzureMLStarter ——它包含了一些示例代碼來訓練識別 MNIST 數字模型。然後,您可以在 VS Code 中打開該克隆庫。
- 繼續閱讀!
# Azure ML 的工作區和門戶
Azure ML 中的一切都圍繞著一個工作區進行組織。這是您提交實驗、存儲數據和結果模型的中心位置。還有一個特殊的Azure ML Portal (opens new window),為您的工作區提供Web 界面,從這裡您可以執行很多操作,如監視您的實驗和指標等等。
您可以通過Azure Portal (opens new window) 的Web 界面創建一個工作區(可參考步驟說明 (opens new window)),或使用Azure CLI(介紹 (opens new window))。
az extension add -n azure-cli-ml
az group create -n myazml -l northeurope
az ml workspace create -w myworkspace -g myazml
工作區包含了一些計算資源。一旦您有了一個訓練腳本,可以提交實驗到工作區,並指定計算目標——這將確保實驗在指定的位置運行,並將實驗的所有結果存儲在工作區,以供將來參考。
# MNIST 訓練腳本
在我們的範例中,我們將展示如何使用 MNIST 數據集來解決非常傳統的手寫數字識別問題 (opens new window)。以同樣的方式,您將能夠運行其他任何訓練腳本。
我們的樣本庫包含簡單的 MNIST 訓練腳本 train_local.py。這個腳本從 OpenML 下載 MNIST 數據集,然後使用 SKLearn 邏輯回歸 訓練模型並打印結果精確度:
mnist = fetch_openml('mnist_784')
mnist['target'] = np.array([int(x) for x in mnist['target']])
shuffle_index = np.random.permutation(len(mist['data']))
X, y = mnist['data'][shuffle_index], mnist['target'][shuffle_index]
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size = 0.3, random_state = 42)
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_hat = lr.predict(X_test)
acc = np.average(np.int32(y_hat == y_test))
print('Overall accuracy:', acc)
當然,我們使用邏輯回歸僅是為了作為示例,並不意味著這是解決這個問題的最好方式……
# 在 Azure ML 中運行腳本
您可以在本地運行此腳本並查看結果。然而,如果我們選擇使用 Azure ML,會給我們帶來兩大好處:
- 在集中式計算資源上調度和運行訓練,其性能通常比本地計算機更強大。 Azure ML 會使用合適的配置將腳本打包到 Docker 容器中。
- 將訓練結果記錄到 Azure ML 工作區內的集中位置。要做到這一點,我們需要將下面的代碼添加到腳本中,用來記錄指標:
from azureml.core.run import Run
...
try:
run = Run.get_submitted_run()
run.log('accuracy', acc)
except:
pass
此腳本修改後的版本被稱為train_universal.py(它比上面呈現的代碼更複雜一些),它既可以在本地運行(不使用 Azure ML),也可以運行在遠程計算資源上。
為了從 VS Code 中運行在 Azure ML 上,請遵循這些步驟:
- 確保您的 Azure 擴展連接到您的雲帳戶。選擇左側菜單的 Azure 圖標。如果您沒有連接,您會看到在右下角顯示一個通知以便您連接(見圖 (opens new window))。點擊它,並通過瀏覽器登錄。您也可以按下 Ctrl-Shift-P,將彈出命令面板,輸入 Azure Sign In 進行登錄。
- 然後,您應該能夠在 Azure 欄部分的 MACHINE LEARNING 中看見您的工作區:
 在這裡,您會看到工作區中的不同對象:計算資源,實驗等。
在這裡,您會看到工作區中的不同對象:計算資源,實驗等。 - 回到文件列表,並用鼠標右鍵點擊
train_universal.py並選擇 Azure ML: Run as experiment in Azure。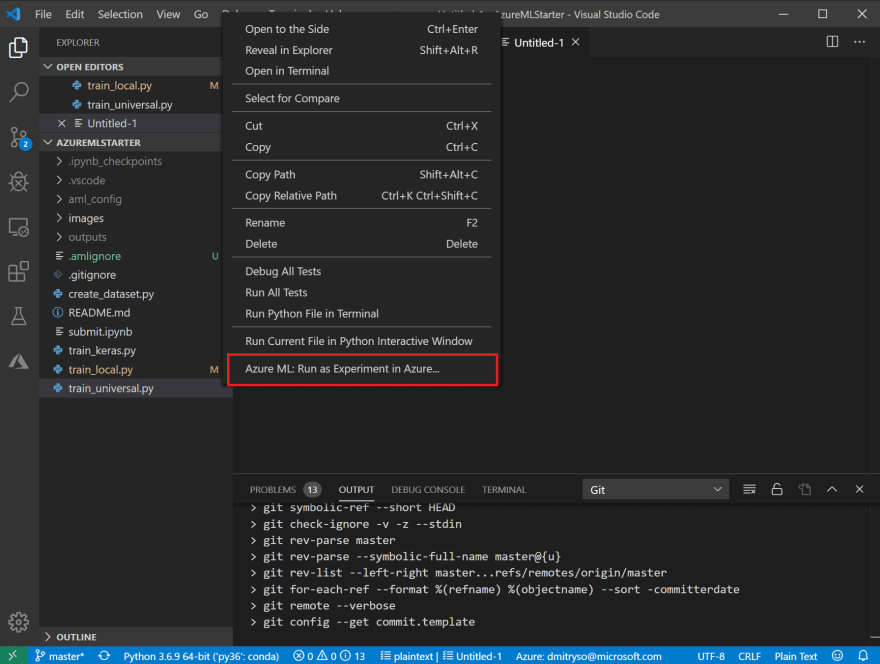
- 確認您的Azure訂閱和您的工作區,然後選擇創建新實驗:



- 創建新的 Compute 和 compute configuration:
- Compute 定義了用於訓練/推理的計算資源。您可以使用本地計算機或任何云資源。在我們的示例中,我們將使用 AmlCompute 集群。請建立 STANDARD_DS3_v2 機器的可擴展群集,節點配置為 min=0和max=4。您可以從 VS Code 中,或從ML 門戶 (opens new window)中進行配置。
 - Compute Configuration 定義遠程資源上創建的用於執行訓練的容器選項。特別是,它指定所有要安裝的庫。在我們的例子中,選擇 SkLearn,並確認庫列表。 VS Code 中的Azure ML 工作區 (opens new window)
- Compute Configuration 定義遠程資源上創建的用於執行訓練的容器選項。特別是,它指定所有要安裝的庫。在我們的例子中,選擇 SkLearn,並確認庫列表。 VS Code 中的Azure ML 工作區 (opens new window)
- 然後您會看到一個窗口,顯示下一個實驗的 JSON 描述。您可以在其中編輯信息,例如改變實驗或集群名稱,並調整一些參數。當您準備好後,點擊 Submit Experiment:

- 在VS Code 中成功提交實驗後,您會得到一個鏈接,指向Azure ML 門戶 (opens new window)中的實驗進度和結果。
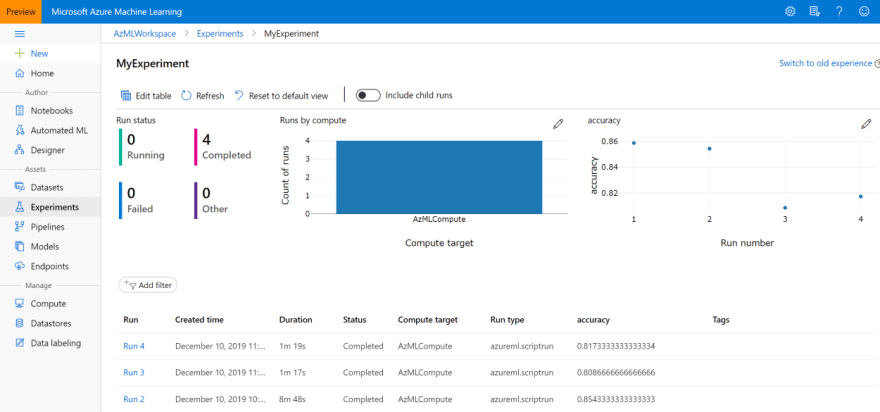 您還可以從Azure ML 門戶 (opens new window) 中的Experiments 選項卡,或VS Code 中的Azure Machine Learning 欄找到您的實驗:
您還可以從Azure ML 門戶 (opens new window) 中的Experiments 選項卡,或VS Code 中的Azure Machine Learning 欄找到您的實驗:
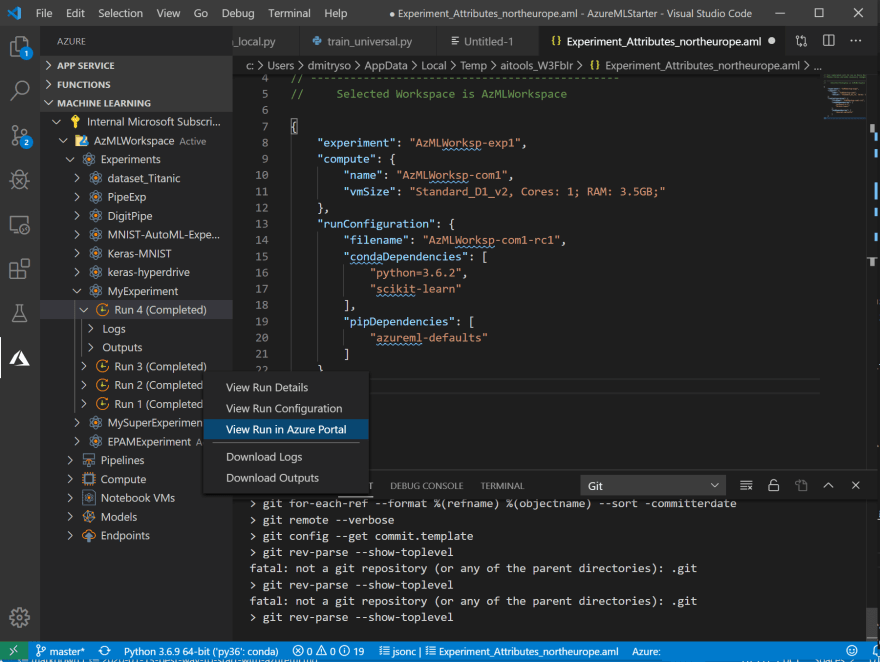
- 在您的代碼調整一些參數後,如果要再次運行實驗,這個過程會更快、更容易。用鼠標右鍵單擊您的訓練文件,您會看到一個新的菜單選項 Repeat last run ——只需選擇它,實驗將立即被提交。
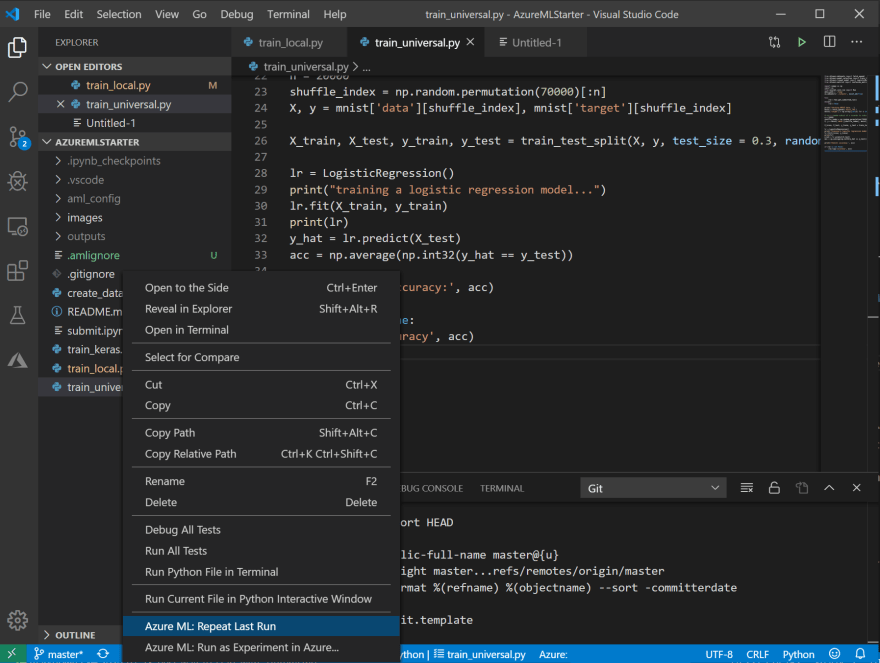 然後,您將在 Azure ML 門戶中看到所有運行的指標結果,如上面的截圖所示。
然後,您將在 Azure ML 門戶中看到所有運行的指標結果,如上面的截圖所示。
現在您已了解,將運行提交到 Azure ML 並不複雜,而且一些功能(如從您的運行、模型等存儲所有的統計數據)是免費的。
您可能已經註意到,對我們的範例來說,在集群上運行腳本所花費的時間比本地運行要長——它甚至可能需要幾分鐘。當然,這需要花一些資源,如將腳本和所有環境打包到容器中,並將其發送到雲端。如果群集被設置為自動縮放到0節點——可能還會有一些額外的開銷,如虛擬機的啟動,並且當這個範例腳本小到僅需要幾秒鐘來執行的時候,這些開銷都是顯而易見的。然而,在現實的場景中,當訓練需要幾十分鐘,有時甚至更多的時候——這種開銷變得幾乎不再重要,尤其是對從集群中獲得的速度提升來說。
# 下一步是什麼?
現在您已經了解瞭如何將腳本提交到遠程群集上來執行,可以開始在您的日常工作中使用 Azure ML了。您可以在一般 PC 上開發腳本,然後在 GPU 虛擬機或集群上自動計劃執行,並在一個地方保存所有的結果。
不過,使用 Azure ML 不僅僅只有這兩個優勢。 Azure ML 也可用於數據存儲和數據集處理——使用不同的訓練腳本來訪問相同的數據會更加方便。另外,您還可以通過 API 自動提交實驗、改變參數——從而進行一些超參數優化。此外,Azure ML 中內置的稱為Hyperdrive (opens new window)的特定技術,能夠進行更聰明的超參數搜索。我將在下一篇文章中討論這些功能和技術。
# 有用的資源
如果您想了解更多信息,Microsoft Learn 提供的以下課程可能會很有用: